OpenAI e ChatGPT: Guida ai vettori di embedding per lo sviluppo software
I dati hanno da sempre svolto un ruolo centrale nello sviluppo di soluzioni software. Una delle maggiori sfide in questo campo è l'elaborazione e l'interpretazione di dati non strutturati, come testi, immagini o file audio. È qui che entrano in gioco i vettori di embedding (o semplicemente embeddings), una tecnologia che sta acquisendo un'importanza crescente nello sviluppo di soluzioni software che integrano funzionalità di intelligenza artificiale.
Gli embeddings sono essenzialmente una tecnica per convertire dati non strutturati in una struttura che può essere facilmente elaborata dal software. Servono a trasformare dati complessi come parole, frasi o persino interi documenti in uno spazio vettoriale, dove elementi simili si trovano vicini tra loro. Queste rappresentazioni vettoriali permettono alle macchine di riconoscere e utilizzare sfumature e relazioni nei dati, il che è essenziale per una vasta gamma di applicazioni come l'elaborazione del linguaggio naturale (NLP), il riconoscimento di immagini e i sistemi di raccomandazione.
OpenAI, il produttore del sistema di intelligenza artificiale ChatGPT, offre modelli, tra gli altri, per la creazione di embeddings per testi. Alla fine di gennaio 2024, OpenAI ha presentato nuove versioni di questi modelli di embedding, che sono più potenti e convenienti rispetto alle loro versioni precedenti. In questo articolo, dopo una breve presentazione generale degli embeddings, approfondiremo gli embeddings di OpenAI e le novità recentemente introdotte, ne discuteremo il funzionamento e analizzeremo come possono essere utilizzati in diversi progetti di sviluppo software.
Embeddings spiegati brevemente
Immaginatevi di essere in una stanza piena di persone e il vostro compito è raggruppare queste persone in base alla loro struttura di personalità. Per farlo, potreste iniziare a porre domande su diverse caratteristiche della personalità. Ad esempio, potreste chiedere quanto una persona sia aperta a nuove esperienze e valutare la risposta su una scala da 0 a 1. A ogni persona viene così assegnato un numero che rappresenta la sua apertura.
Successivamente, potreste chiedere un'altra caratteristica della personalità, come il grado di coscienziosità, e assegnare nuovamente una valutazione tra 0 e 1. Ora ogni persona ha due numeri che insieme formano un vettore in uno spazio bidimensionale. Ponendo ulteriori domande su diverse caratteristiche della personalità e valutandole in modo simile, potete creare un vettore multidimensionale per ogni persona. In questo spazio vettoriale, le persone che hanno vettori simili possono essere considerate simili in termini di personalità.

Nel mondo dell'intelligenza artificiale, utilizziamo gli embeddings per trasformare dati non strutturati in uno spazio vettoriale n-dimensionale. Analogamente alle caratteristiche della personalità delle persone nella stanza, ogni punto in questo spazio vettoriale rappresenta un elemento dei dati originali (come una parola o una frase) in un modo che sia comprensibile ed elaborabile per i computer.
Embeddings di OpenAI
Gli embeddings di OpenAI estendono questo concetto fondamentale. Invece di utilizzare semplici caratteristiche come i tratti della personalità, i modelli di OpenAI sfruttano algoritmi avanzati e grandi quantità di dati per ottenere una rappresentazione molto più profonda e sfumata dei dati. Il modello non analizza solo singole parole, ma considera anche il contesto in cui queste parole vengono utilizzate, il che porta a rappresentazioni vettoriali più precise e significative.
Un'altra differenza importante è che gli embeddings di OpenAI si basano su modelli di machine learning altamente sofisticati, che possono apprendere da un'enorme quantità di dati. Ciò significa che sono in grado di riconoscere modelli e relazioni sottili nei dati. Essi vanno ben oltre ciò che potrebbe essere ottenuto con una semplice scalatura e dimensionamento, come nell'analogia iniziale. Questo porta a una capacità significativamente migliorata di riconoscere e utilizzare somiglianze e differenze nei dati.
I singoli valori non sono significativi
Mentre nell'analogia con le caratteristiche della personalità ogni singolo valore di un vettore permette di dedurre direttamente una caratteristica concreta – ad esempio, l'apertura a nuove esperienze o la coscienziosità –, questo legame diretto non esiste più negli embeddings di OpenAI. In questi embeddings non si può semplicemente considerare isolatamente un singolo valore del vettore e dedurne proprietà specifiche dei dati di input. Ad esempio, da un determinato valore nel vettore di embedding di una frase non si può dedurre direttamente quanto quella frase sia amichevole o negativa.
La ragione di ciò risiede nel modo in cui i modelli di machine learning codificano le informazioni. Questo è particolarmente vero per quelli utilizzati per la creazione di embeddings. I modelli lavorano con rappresentazioni complesse e multidimensionali, dove il significato di un singolo elemento (come una parola in una frase) è determinato dall'interazione di molte dimensioni nello spazio vettoriale. Ogni aspetto dei dati originali – che sia il tono di un testo, l'atmosfera di un'immagine o l'intenzione dietro un'espressione parlata – viene catturato dall'intero spettro del vettore e non da singoli valori all'interno di esso.
Pertanto, quando si lavora con gli embeddings di OpenAI, è importante capire che l'interpretazione di questi vettori non è intuitiva o diretta. Sono necessari algoritmi e analisi per trarre conclusioni significative da questi vettori ad alta dimensione e densamente codificati.
Confronto di vettori con la similarità del coseno
Un elemento centrale nella gestione degli embeddings è la misurazione della somiglianza tra diversi vettori. Uno dei metodi più comuni per questo è la **Cosine Similarity** (**similarità del coseno**). Questa misura viene utilizzata per determinare quanto due vettori – e quindi i dati che essi rappresentano – siano simili.
Per chiarire il concetto, iniziamo con un semplice esempio in due dimensioni. Immaginate due vettori in un piano, ciascuno rappresentato da un punto nel sistema di coordinate. La **Cosine Similarity** tra questi due vettori è determinata dal coseno dell'angolo tra di essi. Se i vettori puntano nella stessa direzione, l'angolo tra di essi è di 0 gradi e il coseno di questo angolo è 1, il che indica la massima somiglianza. Se i vettori sono ortogonali (cioè, l'angolo è di 90 gradi), il coseno è 0, il che indica assenza di somiglianza. In caso di orientamento opposto (180 gradi), il coseno è -1, il che indica la massima dissimilitudine.
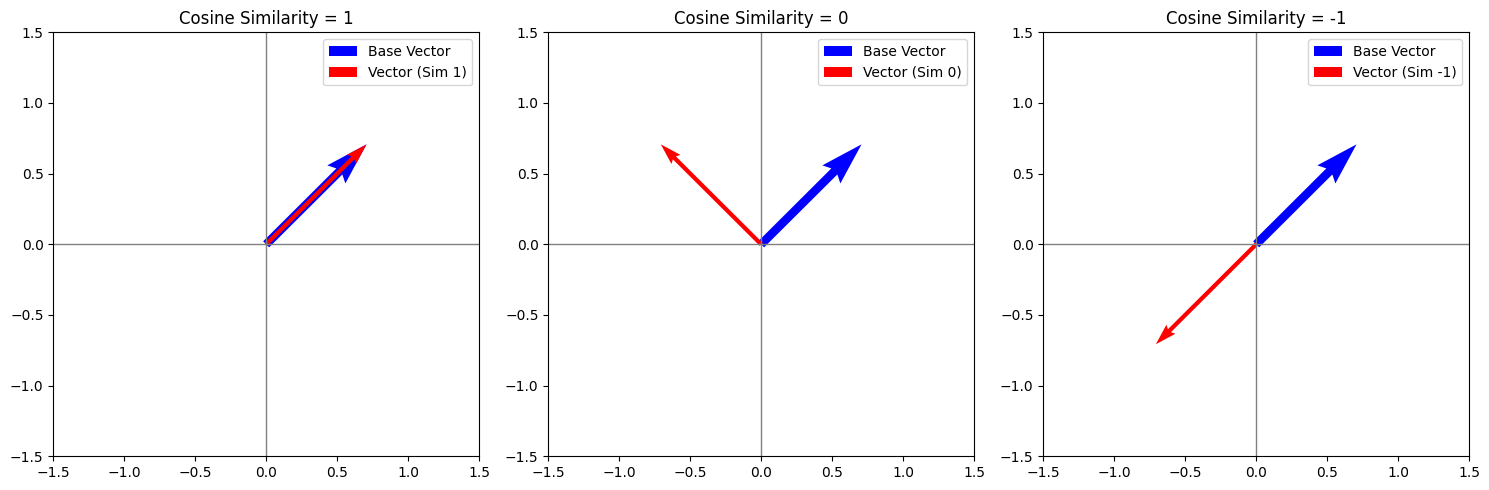
Abbildung 1: Kosinusähnlichkeit
Python Notebook per provare
A corredo di questo articolo è disponibile un **Google Colab Python Notebook** [1], con il quale si possono provare molti degli esempi qui illustrati. Colab, abbreviazione di Colaboratory, è un servizio cloud gratuito offerto da Google. Permette di scrivere ed eseguire codice Python direttamente nel browser. Colab si basa sui Jupyter Notebooks, una popolare applicazione web open source che consente di combinare codice, equazioni, visualizzazioni e testo in un unico formato simile a un documento. Il servizio Colab è ben adatto per esplorare e sperimentare con l'API di OpenAI utilizzando Python.